Il suffit de déclarer le réplica, le nouveau serveur que nous appellerons ldap2.martymac.com et le fichier
"replog" dans lequel les changements à la base seront répertoriés. Ce fichier sera lu par slurpd qui se
connectera au serveur LDAP esclave pour modifier sa base. Modification du fichier slapd.conf de ldap1.martymac.com :
include /etc/ldap/schema/core.schema
include /etc/ldap/schema/cosine.schema
include /etc/ldap/schema/inetorgperson.schema
include /etc/ldap/schema/nis.schema
include /etc/ldap/schema/samba.schema
pidfile /var/run/slapd.pid
argsfile /var/run/slapd.args
database ldbm
suffix "dc=martymac,dc=com"
rootdn "cn=Manager,dc=martymac,dc=com"
rootpw secret
directory /var/lib/ldap
index objectClass,rid,uid,uidNumber,gidNumber,memberUid eq
index cn,mail,surname,givenname eq,subinitial
replogfile /var/lib/ldap/replog
replica host=ldap2.martymac.com:389
binddn="cn=Manager,dc=martymac,dc=com"
bindmethod=simple
credentials="secret"
Déclaration du DN autorisé à répliquer sa base et du serveur maître auquel se reporter en cas de demande de
modification des données. Ceci se fait via le fichier slapd.conf du serveur esclave ldap2.martymac.com :
include /etc/ldap/schema/core.schema
include /etc/ldap/schema/cosine.schema
include /etc/ldap/schema/inetorgperson.schema
include /etc/ldap/schema/nis.schema
include /etc/ldap/schema/samba.schema
pidfile /var/run/slapd.pid
argsfile /var/run/slapd.args
database ldbm
suffix "dc=martymac,dc=com"
rootdn "cn=Manager,dc=martymac,dc=com"
rootpw secret
directory /var/lib/ldap
index objectClass,rid,uid,uidNumber,gidNumber,memberUid eq
index cn,mail,surname,givenname eq,subinitial
updatedn "cn=Manager,dc=martymac,dc=com"
updateref "ldap://ldap1.martymac.com"
Note : Pour des raisons de clarté, nous avons utilisé ici le rootdn du serveur esclave pour effectuer les mises
à jour, mais il est normalement conseillé d'utiliser un autre dn créé spécialement pour l'opération, disposant
de droits spéciaux. (Cf. http://www.openldap.org/doc/admin21/replication.html).
Il reste à démarrer les démons slapd et slurpd sur le serveur maître et le démon slapd sur le serveur esclave.
Les deux serveurs sont désormais prêts à se répliquer. Cependant, comment interroger l'un ou l'autre en fonction
de leur état de fonctionnement ?
Nous allons avoir besoin d'un mécanisme de failover... Le mécanisme d'IP virtuelle peut facilement s'en charger,
approfondissons un peu le sujet après quelques remarques...
Les explications ci-dessus sont valables pour une base vierge, car slurpd n'envoie au serveur LDAP esclave que les
modifications apportées à la base. Si votre base contient déjà des informations, suivez cette manipulation sur le
serveur maître :
- Dumpez la base dans un fichier : ldapsearch -b 'dc=martymac,dc=com' -xh ldap1.martymac.com > dump.ldiff
- Supprimez dans ce fichier les quelques lignes de fin contenant les informations globales sur la recherche
- Eteignez slapd et slurpd
- "Backupez" vos fichiers de base situeés dans /var/lib/ldap : tar cvzf /tmp/ldap.back.tgz /var/lib/ldap
- Supprimez les fichiers de la base : rm -rf /var/lib/ldap/*
- Démarrez les démons slapd et slurpd
- Enfin, insérez le contenu du fichier de dump : ldapadd -W -D 'cn=Manager,dc=martymac,dc=com' -xh localhost -f dump.ldiff
- Vous devriez retrouver votre base initiale sur le serveur maître ET sur le serveur esclave qui aura reçu les mises à jour.
Note : Nous avons ici dumpé la base avec ldap-search, mais il est également possible d'utiliser slapcat, ou de
simplement copier les fichiers de données situés dans /var/lib/ldap.
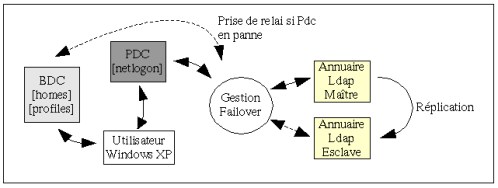
Nous avons vu comment implémenter des serveurs LDAP redondants, mais comment faire pour interroger l'un ou l'autre en
fonction de leur état ? Avoir des serveurs disposant des même informations mais ne pas pouvoir interroger le serveur
B si le serveur A tombe en panne ne serait d'aucune utilité : il faut mettre en place un système de tolérance de
panne.
La méthode que nous allons étudier est très simple : elle consiste à passer par une addresse IP virtuelle. Chaque
serveur LDAP possède sa propre adresse IP, mais en possède aussi une seconde qui sera commune à tous les serveurs
redondants (un "alias"). Les serveurs demeurent acessibles via leur "vraie" adresse IP, mais le sont désormais aussi
par leur nouvelle adresse. Côté client (Samba), nous interrogerons la base LDAP via l'adresse IP virtuelle commune
(et non la "vraie" adresse). Le passage d'un serveur à l'autre se fera par une modification de la table de routage
du poste client, ceci de manière totalement transparente pour l'application : si le premier serveur tombe en panne,
les données sont immédiatement redirigées vers le second.
Nous abordons là la partie la plus difficile du sujet : la détection de la panne et la remontée d'information. Ceci
peut se faire via un protocole de routage mais nous nous contenterons ici d'un script qui testera en permanence
l'état des serveurs et qui modifiera la table de routage, méthode simple à mettre en place et facilement contrôlable.
Il existe bien d'autres méthodes de tolérance de panne, notamment NAT (Network Address Translation) ou le routage
dynamique (via l'utilisation d'un protocole de routage), mais elles impliquent souvent un matériel intermédiaire
(routeur ou ordinateur). Le principe général reste cependant le même que celui que nous allons appliquer ici : rendre
la panne transparente au client par un mécanisme de sélection du chemin. La solution que nous avons choisie est peu
onéreuse : aucun matériel supplémentaire n'est nécessaire ; elle n'est cependant pas conseillée dans un environnement
de production !
Quelques concepts :
- Il faut forcer le client à consulter sa table de routage pour sélectionner le chemin que les packets doivent
prendre. En d'autres termes, l'adresse IP virtuelle ne doit pas être sur le même (sous-)réseau IP que le client.
En effet, si le serveur distant est sur le même (sous-)réseau que le client, les packets pourront être acheminés
sans passer par une "machine" tierce (routeur, mais en fait notre vraie IP), ce qui, dans notre cas, ne nous
intéresse pas. Pour sélectionner notre chemin, nous allons donc indiquer au client que l'adresse IP virtuelle
(non joignale) peut être contactée en utilisant une passerelle qui n'est autre que la "vraie" adresse IP du serveur
LDAP à contacter. Celui-ci se chargera de la transmission des packets à son interface virtuelle. Voilà comment
nous allons sélectionner nous même le "bon" serveur LDAP.
- L'utilisation de nos serveurs LDAP comme gateways implique aussi que leurs vraies IP soient dans le même
(sous-)réseau IP que le client.
En résumé :
Sur le PDC samba :
- Configuration de Samba et des services clients LDAP pour interroger le serveur LDAP via son adresse IP virtuelle.
- Sa table de routage lui indiquera par où passer pour atteindre l'adresse IP virtuelle du serveur LDAP.
- Modification dynamique de sa table de routage, via un script, en fonction de l'état des serveurs.
Sur les serveurs LDAP :
- Vraies Adresses IP dans le même (sous-)réseau que le client (pour servir de gateway).
- Ajout d'une interface virtuelle ayant une adresse IP commune à tous les serveurs redondants, mais appartenant à un sous-réseau différent pour forcer le routage.
- Réplication des données de l'annuaire entre les serveurs, via leurs vraies adresses IP.

#!/bin/sh
# Script scrutant IP1 et IP2, et modifiant la table de routage
# en fonction de l'état des machines. Necessite nmap.
# Ganaël LAPLANCHE
# IP virtuelle du groupe de serveurs
VIP="192.168.2.10"
# Interface de sortie de notre client
IFACE="eth0"
# Premier serveur
IP1="192.168.1.11"
METRIC1="0"
# Deuxième serveur
IP2=" 192.168.1.14"
METRIC2="5"
# Tests a effectuer
# Port distant
TESTPORT="389"
# Nom du service
TESTSERV="ldap"
# Protocole
TESTPROTO="tcp"
# Attente entre chaque boucle
WAIT="5"
while true; do
echo "[Test de ${IP1}]"
nmap -sT ${IP1} -p ${TESTPORT} | grep "${TESTPORT}/${TESTPROTO}[ ]*open[ ]*${TESTSERV}" > /dev/null
if [ $? -eq 0 ]; then
route add -host ${VIP} metric ${METRIC1} gw ${IP1} dev ${IFACE} > /dev/null
echo "${IP1} -- Ok : routage pour ${VIP}, metrique ${METRIC1}"
else
route del -host ${VIP} metric ${METRIC1} gw ${IP1} dev ${IFACE} > /dev/null
echo "${IP1} !Ok : stop routage"
fi
echo "[Test de ${IP2}]"
nmap -sT ${IP2} -p ${TESTPORT} | grep "${TESTPORT}/${TESTPROTO}[ ]*open[ ]*${TESTSERV}" > /dev/null
if [ $? -eq 0 ]; then
route add -host ${VIP} metric ${METRIC2} gw ${IP2} dev ${IFACE} > /dev/null
echo "${IP2} -- Ok : routage pour ${VIP}, metrique ${METRIC2}"
else
route del -host ${VIP} metric ${METRIC2} gw ${IP2} dev ${IFACE} > /dev/null
echo "${IP2} !Ok : stop routage"
fi
sleep ${WAIT}
echo "-------------------------"
done
exit 0